SPM Maps: "Blobs"How are those activation "blobs" on an fMRI image created, and what exactly do they represent?
|

|
Brightly colored "blobs" on fMRI maps represent brain regions or voxels where "statistically significant" levels of activation or correlation are thought to have occurred. The size and number of these blobs are somewhat arbitrarily chosen, however, involving tradeoffs between excluding false positives (saying an area activates when it does not) and accepting false negatives (considering an area to be silent when it really does activate).
The first level coloring decision is typically based on calculation of a so-called test statistic (e.g., a T-, F- or Z-score) for each voxel or brain region from the fMRI data. Under the null hypothesis that no true activation has occurred, a p-value can be determined, representing the probability that the calculated test statistic score or larger has occurred by chance. Whenever the p-value is less than an arbitrary preselected level of significance, we conclude the measurement is unlikely to have occurred by chance and classify the voxel as "activated/correlated".
The first level coloring decision is typically based on calculation of a so-called test statistic (e.g., a T-, F- or Z-score) for each voxel or brain region from the fMRI data. Under the null hypothesis that no true activation has occurred, a p-value can be determined, representing the probability that the calculated test statistic score or larger has occurred by chance. Whenever the p-value is less than an arbitrary preselected level of significance, we conclude the measurement is unlikely to have occurred by chance and classify the voxel as "activated/correlated".
Most fMRI analysis programs include "slider bars" allowing interactive display of blobs at various p-value thresholds. As seen below, moving this slider bar toward more restrictive p-values reveals successively smaller areas of activation. But which level is the correct one?
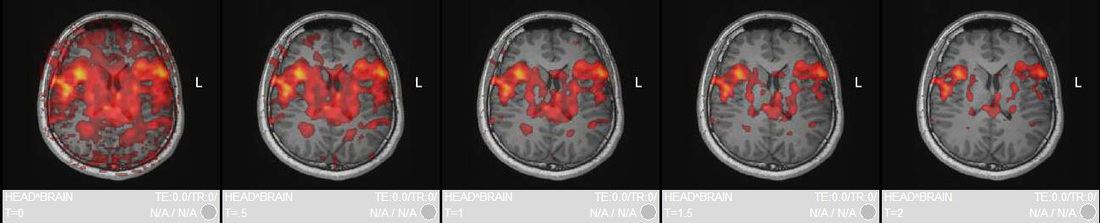

BOLD word generation study. The same image has been processed using T-scores ranging from 0 (upper left) to 4.5 (lower right), corresponding to two-sided p-values between 1.000000 and 0.000007. Which one is correct? For simple eloquent cortex mapping an arbitrary selection in the intermediate range is often made by selecting a "visually pleasing" and/or "modest" amount of activity.
There is no simple answer. Although p-values of 0.05 are commonly used in "standard" scientific experiments, this threshold is inappropriate for fMRI studies where simultaneous statistical testing must be performed on 100,000 or more voxels. Setting a p-value of 0.05 for a single voxel means that 5000 (100,000 x 0.05) of these voxels could appear falsely activated. This is an example of the so-called multiple comparisons problem, a major issue that affects genetics testing as well. Methods for handling this including the Bonferroni correction are described in the Advanced Discussion.
In addition to selecting a p-value threshold, several other arbitrary decisions about blobs must be made. These include: 1) choosing the actual color palette including the range of p-values for corresponding to different shades or hues; 2) whether to employ additional spatial smoothing (makes the map less noisy but smears data anatomically); 3) whether and how to perform clustering (e.g., deciding to color a voxel only when a certain small number of immediate neighbors also appear to be activated to reduce false positives). Each of these decisions can significantly affect the appearance of the map.
Because of the problems in defining the limits and meanings of "blobs", some neuroscientists have disparagingly called the field of fMRI "blobology". The next two Q&A's will address issues concerning false activation and problems with various statistical methods.
References
Colquhoun D. An investigation of the false discovery rate and the misinterpretation of p-values. R Soc Open Sci 2014; 1:140216.
Cohen J. The earth is round (p < .05). Am Psychologist 1994; 49:997-1003.
Engel SA, Burton PC. Confidence intervals for fMRI activation maps. PLOS ONE 2013; 8:e82419. (Paper demonstrating some of the errors made by naive viewers in their interpretation of activation maps, including the false idea that it is possible to compare brain areas based on their map colors.)
Goodman S. A dirty dozen: twelve p-value misconceptions. Semin Hematol 2008; 45:135-140.
Nichols TE. Multiple testing corrections, nonparametric methods, and random field theory. NeuroImage 2012; 62:811-815.
Nichols T, Hayasaka S. Controlling the familywise error rate in functional neuroimaging: a comparative review. Stat Methods Med Res 2003; 12:419-446.
Colquhoun D. An investigation of the false discovery rate and the misinterpretation of p-values. R Soc Open Sci 2014; 1:140216.
Cohen J. The earth is round (p < .05). Am Psychologist 1994; 49:997-1003.
Engel SA, Burton PC. Confidence intervals for fMRI activation maps. PLOS ONE 2013; 8:e82419. (Paper demonstrating some of the errors made by naive viewers in their interpretation of activation maps, including the false idea that it is possible to compare brain areas based on their map colors.)
Goodman S. A dirty dozen: twelve p-value misconceptions. Semin Hematol 2008; 45:135-140.
Nichols TE. Multiple testing corrections, nonparametric methods, and random field theory. NeuroImage 2012; 62:811-815.
Nichols T, Hayasaka S. Controlling the familywise error rate in functional neuroimaging: a comparative review. Stat Methods Med Res 2003; 12:419-446.