General Linear Model (GLM)I don't really understand how GLM works. Can you explain it more completely?
|

|
Don't be discouraged. The General Linear Model (GLM) can be daunting to those with little background in statistics or matrix algebra, but I'll try to make it more understandable here. This is a worthwhile endeavor, as GLM has been the most widely used technique for analyzing task-based fMRI experiments for the past 25 years and is the default method provided by vendors for their clinical fMRI packages.
GLM can be thought of as an extension of a more familiar statistical technique: linear regression. Linear regression, sometimes called trend-line analysis, is a method used to calculate the "best fitting" line for a set of experimental data. Linear regression software is widely available in popular graphics and spreadsheet packages such as Microsoft Excel.
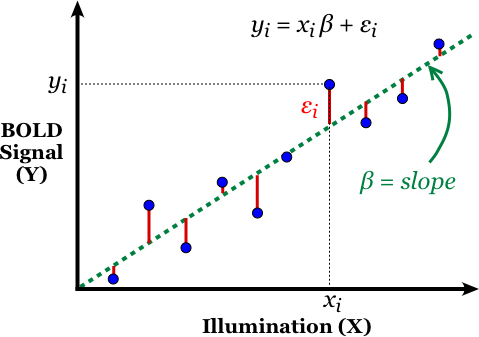
Simplified linear regression example, adapted from
data of Hansen et al (2004)
As an application of linear regression, let us examine how the mean fMRI signal (Y) of a voxel in the visual cortex responds to increasing levels of retinal illumination (X). Plotting our data on a graph (left) we discern a fairly linear relationship between X and Y. Linear regression software computes the “best fitting” straight line for this data. For each data point (xi, yi) the relationship can be written yi = xiβ + εi, where β is the calculated slope of the line and εi is the calculated error (or residual) distance between the line and corresponding data point. Note that the xi values are determined by the design of the experiment, the yi values are measured, while β and the εi's are calculated by the software.
A required assumption for linear regression is that the errors (εi) are random and independent, following a Gaussian distribution with mean of zero. The “best fitting” line is defined to be the one that minimizes the sum of the squared errors (ε1² + ε2² + ε3² + …) between the points and the chosen line. Note that although the calculated slope (β) is the same for each data point (xi, yi), the individual errors (εi) will differ.
Our simple linear regression example has actually produced n separate equations, each of the form yi = xiβ + εi, where n is the number of data points acquired for each time interval i. Matrix algebra allows us to condense this set of equations into a more manageable form. We do this by defining Y, X, and ε as "column vectors", each containing a list of individual measured or calculated values. Specifically,
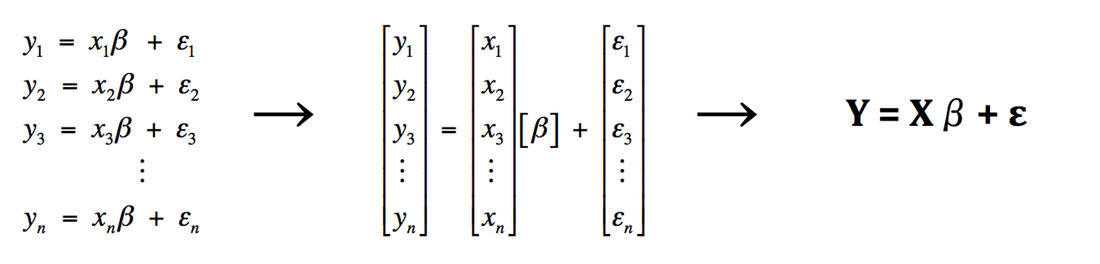
If you are not familiar with matrix algebra or need a simple review, check out Coolmath.com
The General Linear Model (GLM) representation of an fMRI experiment retains the same basic form (Y = Xβ + ε) as does our simple linear regression example. Stated in words, the GLM says that Y (the measured fMRI signal from a single voxel as a function of time) can be expressed as the sum of one or more experimental design variables (X), each multiplied by a weighting factor (β), plus random error (ε).
In GLM both Y and ε remain as single column vectors containing fMRI signal data (yi) or error estimates (εi) respectively for a single voxel at successive time points (i = 1 to n). The experimental design matrix (X), however, is typically much more complex, consisting of perhaps 5-10 columns instead of only one. Each new column of X would be constructed by the investigator to reflect a specific factor (“regressor”) thought to influence the outcome of the experiment.
In GLM both Y and ε remain as single column vectors containing fMRI signal data (yi) or error estimates (εi) respectively for a single voxel at successive time points (i = 1 to n). The experimental design matrix (X), however, is typically much more complex, consisting of perhaps 5-10 columns instead of only one. Each new column of X would be constructed by the investigator to reflect a specific factor (“regressor”) thought to influence the outcome of the experiment.
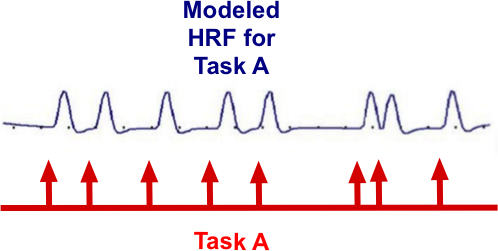
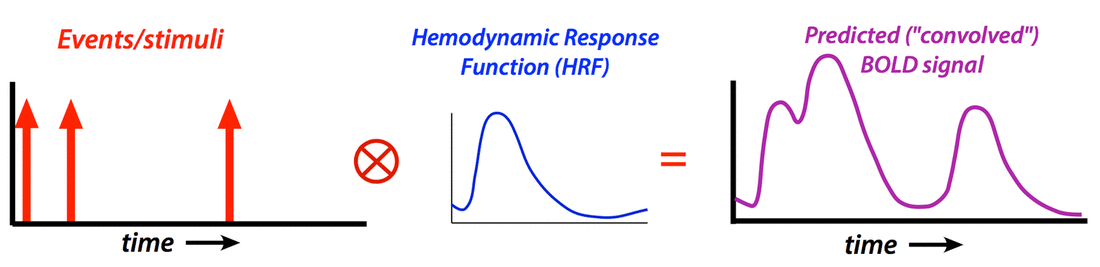
Essential regressors (also known as regressors of interest) are a set of idealized predictions of what the hemodynamic response function (HRF) should look like if a voxel of interest became activated due to a task or stimulus. For example, consider a simple event-related fMRI experiment where a subject is given three tasks (A, B, and C) — such as listening to sounds at three different frequencies presented in random order. if the stimuli for Task A were applied at times denoted by the red arrows above, the predicted response of a receptive voxel in the auditory cortex might be a train of slightly-delayed, short-duration HRFs as illustrated. Numerical values (X i,1) corresponding time points of this predicted response pattern to Task A would then be transferred to and listed vertically in the first column of the GLM design matrix (illustrated below). The predicted responses to tasks B and C would likewise be created and used to fill the second and third columns of the design matrix (X).
The last 7 columns of our design matrix example are considered covariates or nuisance regressors – experimental factors that confound the analysis (such as head motion or signal drifts) but which are of no particular interest by themselves. The data filling these columns may be empirically determined (e.g., actual measurements of head translations and rotations obtained during the experiment) or modeled (e.g., by a linear trend or oscillating basis functions).
Because the design matrix (X) now contains multiple columns, the weighting parameter (β) will no longer be a single number as it was in the simple linear regression example. Fitting data in a full GLM experiment means that β will now become a column vector with values (β1, β2, …, βp), each reflecting the relative contribution of each design factor (Xi) to the fMRI signal. Hence the amplitude vector (β) must have the same number of rows as the design matrix (X) has columns.

Depiction of the General Linear Model (GLM) for a voxel with time-series Y predicted by a design matrix X including 10 effects (three regressors of interest – e.g., tasks A,B,C – and seven nuisance regressors – e.g., six motion parameters and one linear drift). Calculated weighting factors (β1 − β10) corresponding to each regressor are placed in amplitude vector β while column vector ε contains calculated error terms (εi) for the model corresponding to each time point i. (From Monti, 2011, under CC BY license)
Two major assumptions are inherent to basic GLM analysis, either one of which may be rightfully challenged. First, GLM is a univariate approach, calculating statistics on a voxel-by-voxel basis and assuming that signals from each voxel are independent of one another. Secondly, the model assumes that the errors are random and independent, following a Gaussian distribution with mean of zero.
 Statistical Parametic Map (SPM)
Statistical Parametic Map (SPM)overlaid on anatomic image
With fMRI data collected and stored in the Y vector and experimental design factors specified in the X matrix, components of the β and ε vectors are then computed using classical or Bayesian approaches. These results can then be statistically interrogated, testing various hypotheses about the regressors alone or in combination. The final output is usually a Statistical Parametric Map (SPM) or Posterior Probability Map (PPM) that is overlaid on an anatomic image or template.
Needless to say, GLM analysis and processing is very complex, and the interested reader should refer to the references provided below as well as to material in the Advanced Discussion.
Needless to say, GLM analysis and processing is very complex, and the interested reader should refer to the references provided below as well as to material in the Advanced Discussion.

References
Hansen KA, David SV, Gallant JL. Parametric reverse correlation reveals spatial linearity of retinotopic human V1 BOLD response. NeuroImage 2004; 23:233-241. (This experiment is the model used for our simplified linear regression example above)
Monti MM. Statistical analysis of fMRI time-series: a critical review of the GLM approach. Front Hum Neurosci 2011; 5(28):1-13, doi: 10.3389/fnhum.2011.00028
Poline J-B, Brett M. The general linear model and fMRI: Does love last forever? Neuroimage 2012; 62:871-880.
Student. The probable error of a mean. Biometrika 1908; 6:1-25. (The original paper by "Student", a pseudonym used by William Sealy Gosset who wished to remain anonymous due to his work in quality assurance of small samples at the Guinness Brewery in Dublin. The letter "t" associated with Student's distribution was supplied by English statistician R. A. Fisher in 1925).
The FIL Methods Group. SPM12 Manual. Wellcome Trust Center for Neuroimaging, London, 2014.
Hansen KA, David SV, Gallant JL. Parametric reverse correlation reveals spatial linearity of retinotopic human V1 BOLD response. NeuroImage 2004; 23:233-241. (This experiment is the model used for our simplified linear regression example above)
Monti MM. Statistical analysis of fMRI time-series: a critical review of the GLM approach. Front Hum Neurosci 2011; 5(28):1-13, doi: 10.3389/fnhum.2011.00028
Poline J-B, Brett M. The general linear model and fMRI: Does love last forever? Neuroimage 2012; 62:871-880.
Student. The probable error of a mean. Biometrika 1908; 6:1-25. (The original paper by "Student", a pseudonym used by William Sealy Gosset who wished to remain anonymous due to his work in quality assurance of small samples at the Guinness Brewery in Dublin. The letter "t" associated with Student's distribution was supplied by English statistician R. A. Fisher in 1925).
The FIL Methods Group. SPM12 Manual. Wellcome Trust Center for Neuroimaging, London, 2014.
Related Questions
How are those activation "blobs" on an fMRI image created, and what exactly do they represent?
How are those activation "blobs" on an fMRI image created, and what exactly do they represent?